在快速迭代和微服務(wù)架構(gòu)盛行的今天,高效、穩(wěn)定、協(xié)同的API管理已成為現(xiàn)代軟件開發(fā),尤其是后端工程團(tuán)隊(duì)的剛性需求。2024年,國產(chǎn)API管理工具Eolink憑借其強(qiáng)大的功能、流暢的體驗(yàn)和深度工程化集成能力,在眾多工具中脫穎而出,成為眾多技術(shù)團(tuán)隊(duì),特別是追求高效與規(guī)范的Go語言高級(jí)工程師的得力助手。本文將結(jié)合親測(cè)體驗(yàn),深入解析Eolink的核心用法,并探討其如何賦能Go高級(jí)工程師的工程管理與服務(wù)治理。
一、Eolink:不止于API文檔的全面管理平臺(tái)
Eolink定位為一站式API協(xié)作平臺(tái),其功能遠(yuǎn)超傳統(tǒng)的API文檔工具。它覆蓋了API的設(shè)計(jì)、調(diào)試、測(cè)試、Mock、監(jiān)控、文檔、治理全生命周期。對(duì)于Go工程師而言,其清晰直觀的界面和強(qiáng)大的自動(dòng)化能力,能顯著降低API維護(hù)成本,提升團(tuán)隊(duì)協(xié)作效率。
二、親測(cè)核心功能與高效用法
1. 智能API設(shè)計(jì)與文檔生成
Eolink支持多種方式快速創(chuàng)建API:
- 可視化設(shè)計(jì):通過表單輕松定義請(qǐng)求/響應(yīng)參數(shù)、數(shù)據(jù)結(jié)構(gòu),支持JSON Schema,對(duì)于定義Go結(jié)構(gòu)體對(duì)應(yīng)的API契約非常友好。
- 代碼導(dǎo)入:可直接解析Go(Gin、Beego等主流框架)的注解或Swagger文件,一鍵生成精美、可交互的API文檔,實(shí)現(xiàn)“代碼即文檔”。
- 同步與變更管理:當(dāng)后端代碼更新時(shí),可以同步更新API文檔,并智能識(shí)別變更點(diǎn),通知前端和測(cè)試人員,確保信息同步。
2. 強(qiáng)大的API調(diào)試與測(cè)試
- 全能調(diào)試器:支持Restful、WebSocket、GraphQL等多種協(xié)議,參數(shù)構(gòu)造靈活,環(huán)境變量、全局腳本功能強(qiáng)大,完美替代Postman。
- 自動(dòng)化測(cè)試:可構(gòu)建復(fù)雜的測(cè)試場(chǎng)景和流程,支持?jǐn)?shù)據(jù)驅(qū)動(dòng)。對(duì)于Go微服務(wù),可以輕松編排多個(gè)API的調(diào)用順序,驗(yàn)證業(yè)務(wù)鏈路。關(guān)聯(lián)性能測(cè)試,在接口測(cè)試后直接進(jìn)行壓測(cè),評(píng)估服務(wù)性能。
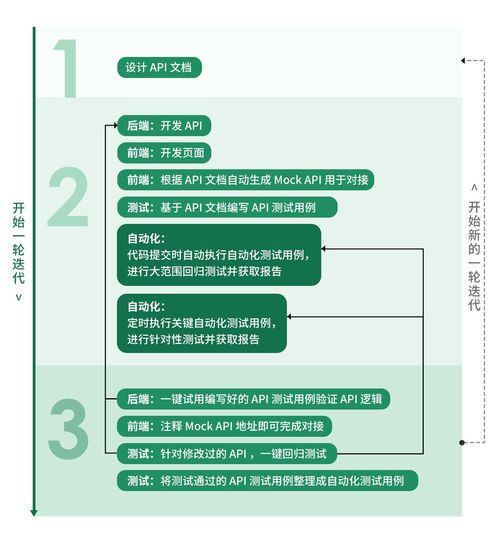
- “一鍵回歸”與持續(xù)集成(CI/CD):這是其殺手锏功能。可將測(cè)試用例與API綁定,任何迭代后,可一鍵運(yùn)行所有關(guān)聯(lián)測(cè)試用例進(jìn)行回歸驗(yàn)證。更重要的是,它提供命令行工具和豐富的API,能無縫集成到Jenkins、GitLab CI/CD流水線中,實(shí)現(xiàn)API的自動(dòng)化測(cè)試與監(jiān)控,保障發(fā)布質(zhì)量。
3. 高效的團(tuán)隊(duì)協(xié)作與項(xiàng)目管理
- 權(quán)限與角色管控:精細(xì)化的項(xiàng)目成員權(quán)限管理,適合中大型團(tuán)隊(duì)。
- 項(xiàng)目與目錄樹:清晰的項(xiàng)目結(jié)構(gòu)管理,方便Go工程師按微服務(wù)模塊組織API。
- 實(shí)時(shí)協(xié)作與評(píng)論:前端、后端、測(cè)試人員可在同一份API文檔上評(píng)論、提問,減少溝通壁壘。
4. Mock服務(wù)與監(jiān)控
- 智能Mock:根據(jù)API定義自動(dòng)生成Mock服務(wù)器,支持豐富的動(dòng)態(tài)mock規(guī)則(如隨機(jī)手機(jī)號(hào)、自定義邏輯),前端開發(fā)不再依賴后端進(jìn)度。
- API監(jiān)控與告警:對(duì)線上核心API進(jìn)行定時(shí)監(jiān)控,一旦出現(xiàn)響應(yīng)超時(shí)、狀態(tài)碼異常等情況,立即通過釘釘、微信、Webhook等渠道告警,助力Go工程師快速定位線上問題。
三、賦能Go高級(jí)工程師:工程管理與服務(wù)治理
對(duì)于Go高級(jí)工程師或技術(shù)負(fù)責(zé)人,Eolink的價(jià)值不僅在于工具本身,更在于其帶來的工程管理范式提升。
1. 標(biāo)準(zhǔn)化與規(guī)范化
通過Eolink強(qiáng)制推行“API先行”或“設(shè)計(jì)即契約”的開發(fā)模式。團(tuán)隊(duì)在開發(fā)前,先在Eolink上共同定義好API接口規(guī)范。這確保了Go后端服務(wù)接口的清晰性、一致性和可維護(hù)性,是構(gòu)建高質(zhì)量、可擴(kuò)展系統(tǒng)的基石。
2. 提升自動(dòng)化水平,保障質(zhì)量
利用其CI/CD集成能力,可以將API自動(dòng)化測(cè)試作為代碼合并和發(fā)布的強(qiáng)制關(guān)卡。每次提交或合并請(qǐng)求,都會(huì)自動(dòng)運(yùn)行相關(guān)的API合約測(cè)試和集成測(cè)試,確保新增代碼不會(huì)破壞現(xiàn)有接口契約,極大提升了Go微服務(wù)體系的穩(wěn)定性和交付信心。
3. 服務(wù)治理與可觀測(cè)性
結(jié)合API監(jiān)控和測(cè)試報(bào)告,Go高級(jí)工程師可以更宏觀地掌控服務(wù)的健康狀態(tài)。通過分析API的響應(yīng)時(shí)間、成功率歷史趨勢(shì),可以為容量規(guī)劃、性能優(yōu)化提供數(shù)據(jù)依據(jù)。Eolink成為了服務(wù)可觀測(cè)性鏈路中的重要一環(huán)。
4. 知識(shí)沉淀與新人上手
所有API文檔、測(cè)試用例、歷史數(shù)據(jù)都沉淀在平臺(tái)中,形成了項(xiàng)目的寶貴知識(shí)庫。新加入團(tuán)隊(duì)的Go工程師可以快速查閱、調(diào)試API,理解系統(tǒng)架構(gòu)和業(yè)務(wù)邏輯,大幅降低 onboarding 成本。
###
總而言之,Eolink在2024年已進(jìn)化為一款功能全面、設(shè)計(jì)專業(yè)的API全生命周期管理平臺(tái)。它從提升個(gè)體開發(fā)效率的工具,演變?yōu)轵?qū)動(dòng)團(tuán)隊(duì)標(biāo)準(zhǔn)化、自動(dòng)化、協(xié)同化工程管理的服務(wù)。對(duì)于致力于構(gòu)建穩(wěn)健、高效后端服務(wù)的Go高級(jí)工程師和技術(shù)團(tuán)隊(duì)而言,引入Eolink不僅意味著選擇了一款“好用”的工具,更是擁抱了一種現(xiàn)代化的、以API為中心的工程管理最佳實(shí)踐,是提升團(tuán)隊(duì)整體研發(fā)效能與軟件質(zhì)量的戰(zhàn)略投資。